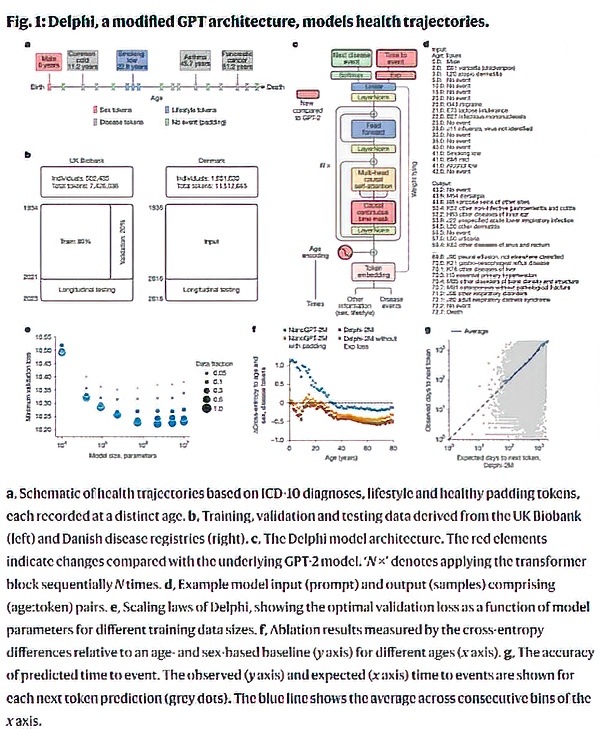
Delphi-2M health trajectory tokens across the lifespan. Pink/red indicates sex tokens, blue lifestyle tokens, green disease tokens, and gray no event (padding) tokens. Ages are annotated at key points from birth to death. This schematic illustrates how the model encodes longitudinal health events for prediction. Adapted from Fitzgerald et al., Nature (2025)