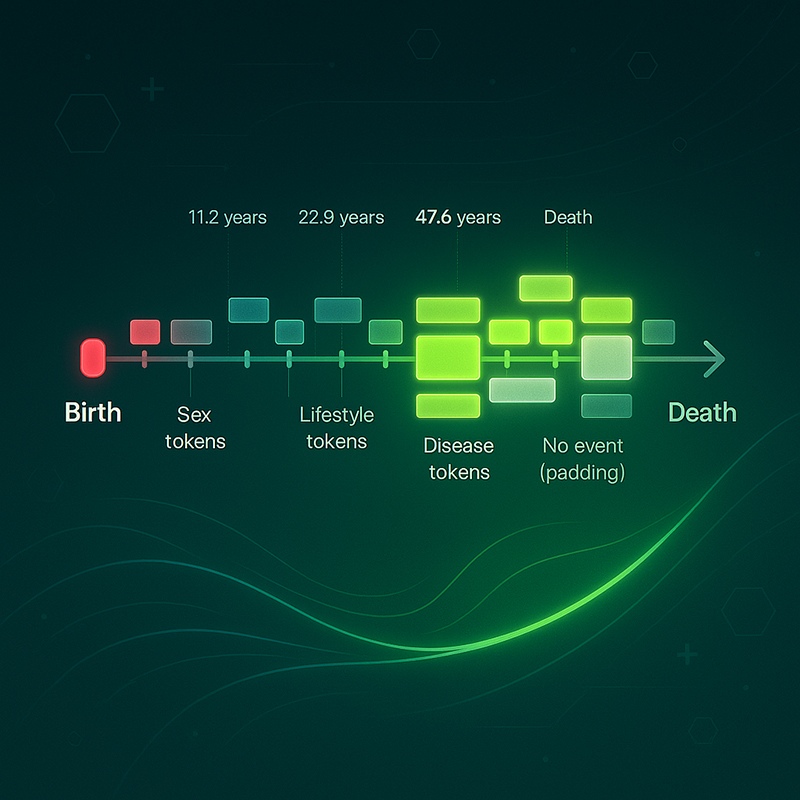

生成式模型可评估1,000多种疾病的风险,并像天气预报一样给出时间预测。如果得到良好验证和管理,它可能将医疗从被动治疗转向主动预防。
预防医学正从事后诸葛亮转变为洞察未来。一个名为Delphi 2M的新型人工智能系统由EMBL欧洲生物信息学研究所、德国癌症研究中心和哥本哈根大学的团队共同开发,能够预测个人在1,000多种疾病上的风险,并将这些概率放置在未来数年的时间线上。
该模型基于来自40万名英国生物银行参与者和190万名丹麦患者的匿名化记录进行训练,学习医疗事件和生活方式因素的模式,然后像天气预报一样以时间速率表达风险。2025年9月17日发表在《自然》杂志上的研究结果显示,其准确性可与领先的单一疾病工具媲美,同时具备模拟未来健康路径以及考虑竞争风险和多病共存的额外能力。我们采访了EMBL EBI的高级科学家汤姆·菲茨杰拉德(Tom Fitzgerald),了解此项目在实践中的可能性。以下引文已为篇幅和清晰度进行编辑。
超越单一评分:建模完整健康轨迹
“从历史上看,很难在大规模的疾病范围和时间跨度上代表大量个体,”菲茨杰拉德解释道。传统方法为每种疾病构建一个模型,而Delphi 2M则同时考虑多种疾病,并将风险映射到时间线上。关键创新包括一个明确的时间编码方案,使团队能够优化接下来会发生什么以及何时可能发生,并可在未来时间点检查校准。“给定某人生活中的任何起点,我们都能生成未来数年的可能轨迹,”他补充说。对于某些疾病,模型的表现能够保持十多年的准确性。该系统是生成式,因此能够采样合成的未来轨迹,以估计一到二十年的潜在疾病负担。
该模型产生的是概率而非确定性,这正是天气预报的类比非常恰当的原因。短期预测通常对急性疾病效果最佳,而长期预测可能更适合慢性疾病。除了点估计外,风险还可以伴随一个人年龄段和疾病的不确定性边界,这有助于向临床医生和患者更清晰地传达信心。
数据输入与输出:人口统计学、遗传学和环境
已发表的模型使用了健康史和少量人口统计学数据作为输入特征:包括吸烟状况、酒精消费、体重指数、年龄和性别。在这个首次发布中,种族并未作为输入特征。此外,尽管团队拥有包含多基因风险评分和HLA等位基因的原型,这些原型能够改善某些疾病的表现并有助于分离糖尿病等疾病中不同的生物学路径,但遗传学也未包含在论文的主要模型中。关于如何在这些模型中最好地表示基因组,目前存在开放的技术问题,但基础系统在没有遗传学的情况下已经表现得非常出色。团队还看到了添加环境和地理信号(例如污染水平)的价值,这将有助于改善预测,并研究风险如何随着社会或环境条件变化。
表现模式、公平性与罕见疾病
与直觉相反,该模型对某些少数群体血统人群和社会较贫困环境中的人群的表现,可能比英国的白人主体队列更好。菲茨杰拉德将此归因于数据密度:疾病更常见的地方有更多信号可供模型学习。但这并不意味着更好的护理。它强调了进行亚组审计、本地验证和重新校准的必要性,以确保在不同人群中公平使用。稀疏的健康记录会降低任何人的表现,包括多数群体。
罕见疾病仍然是更困难的挑战。模型的表现会随着更大数据集和更丰富历史而改善。当前模型使用ICD 10代码的层级,旨在特异性与数据充分性之间取得平衡。通过更大的训练队列,团队可以对更具体的代码层级进行建模,这可能有助于解决非常罕见的疾病。这项研究的价值也可能来自缩短诊断奥德赛的早期警告,而不仅仅是头条准确性数字。
从实验室到临床
Delphi 2M目前还不是临床工具。“在临床应用之前,需要更多测试、评估和政策审查,”菲茨杰拉德说。近期前景在于标记未来一到两年风险上升的早期警告工作流程,以及帮助系统预测跨地区和提供商需求的资源规划。EMBL临时执行主任尤安·伯尼建议患者可能在几年内受益。菲茨杰拉德补充说,个体层面的早期警告可能需要五到十年,因为这将需要前瞻性试验、外部验证、不确定性的谨慎呈现以及临床医生友好的界面。该小组已经以研究身份与临床医生合作,了解哪些信息最有用。
治理、可移植性与漂移
该模型在英国生物银行训练,在保留的英国集合上评估,然后转移到丹麦,其性能仅有轻微下降,这表明它学到了跨系统泛化的模式。即便如此,在其他地方的任何使用都需要本地验证和校准。来自英国训练的衍生模型权重已返回给英国生物银行,并根据该计划的治理规则进行访问。对个人的预测需要个人层面的数据,这将保持在本地机构的控制之下。仅从模型权重重新识别被认为不太可能,但并非不可能,因此治理谨慎进行。
真实部署必须规划分布偏移,因为编码实践、人群和政策会发生变化。团队尚未运行专门的纵向漂移研究。COVID是一个明显的案例研究,可以揭示大流行前后医疗服务和疾病率如何不同,以及模型应该如何适应。任何临床使用都需要监控、回滚计划和人在环路的保护措施。
为什么采用生成式方法
生成式建模使系统能够在时间上表示竞争风险和多病共存,这对于传统的每病种模型(如Cox回归)来说是困难的。这种统一方法有助于在时间和疾病状态上对齐大量人群,并支持个体层面和人群层面的问题,从可能的下一个事件到多年资源规划。
谁构建了它,花了多长时间
菲茨杰拉德是EMBL EBI的高级科学家,在大规模队列分析和基因组学方面有二十多年经验。他此前在韦尔康桑格研究所从事解密发育障碍项目,这是英国首个针对罕见病具有直接临床应用的大型测序工作,在过去十年中与尤安·伯尼在EMBL EBI共同运营研究小组。Delphi 2M从构思到功能系统大约用了一年半时间,到发表大约两年时间,剑桥和海德堡的多个团队做出了贡献。
未来发展
团队正在通过添加更多数据模态(包括遗传学和环境背景)来改进模型,并研究如何以临床医生可以使用的方式最好地呈现风险和不确定性。成功将通过根据预测采取行动是否改善结果、减少不平等并避免伤害来衡量。
结论
Delphi 2M标志着预测医学的一个重要步骤:一个为许多疾病计时风险并描绘可能前进道路的模型。在英国和丹麦数据上的《自然》结果是强有力的。然而,临床使用取决于前瞻性试验、公平性审计、治理以及谨慎整合到工作流程中。提前数年展望的技术能力现在已经存在。任务是确保这种远见对它旨在服务的人们是有用的、公平的和安全的。
声明:本文所引用内容已为篇幅与表述清晰度进行编辑,仅供信息参考,不构成医疗建议。